In the rapidly evolving world of business automation, invoice processing remains one of the most impactful applications of AI and machine learning. Tools like Amazon Textract, Google Document AI, and Azure Document Intelligence aim to eliminate manual data entry, reduce errors, and accelerate operations — but how do they actually perform under real-world conditions?
As demand grows for automated invoice recognition, so do the questions businesses are asking:
- What’s the best alternative to Amazon Textract?
- Is Azure’s Document Intelligence significantly more accurate?
- How does AWS Textract compare to Google Document AI?
To answer these questions, we conducted a detailed benchmark of five leading AI services:
- AWS Textract (AnalyzeExpense)
- Google Document AI (Invoice Parser)
- Azure Document Intelligence
- GPT-4o with third-party OCR (GPTt)
- GPT-4o with image input (GPTi)
Each system was tested on a diverse dataset of real invoices — spanning multiple layouts, formats, and time periods — and evaluated on key fields such as vendor names, invoice totals, and itemized line entries. We also measured speed and cost to provide a comprehensive view of how each tool performs in practical use.
Whether you're migrating away from AWS Textract, comparing Azure and Google options, or exploring the next generation of document AI, this analysis will give you the technical insights you need to make an informed decision.
IDP Models Benchmark
We are constantly testing large language models for business automation tasks. Check out the latest results.
AI Model Selection Criteria
We have carefully evaluated dozens of AI models and services for document processing to choose the most optimal selection for the purposes of processing invoices real-world projects:
- Popularity: Popular services and AI models tend to have better support and more extensive documentation, making them easier to implement,
- Invoice Processing Capability: Generic document processing AI models always require adjustments and fine tuning to process specific documents, which is why we’ve focused on testing models and services already specialize in processing invoices,
- API Integration: The ability of a model or a service to be integrated via API allows them to be easily integrated into applications, resulting in highly performant, secure, and scalable products.
Tested Document Automation Tools
Given these criteria, we have chosen five AI models able to recognise invoices. We’ve given each one a nickname for ease of understanding:
- Amazon Analyze Expense API, or “AWS”,
- Azure AI Document Intelligence - Invoice Prebuilt Model, or “Azure”,
- Google Document AI - Invoice Parser, or “Google”,
- GPT-4o API - text input with 3rd party OCR, or ”GPTt”,
- GPT-4o API - image input, or “GPTi”.
All five models are specialised in analysing invoices, have API integration capabilities and are very popular in the field of smart document analysis.
Build a Smarter Invoice Automation Engine
Invoice Dataset
We have put together a dataset containing scanned digital invoices in the following formats: JPG, PNG, PDF (without a text layer). All scans are of high quality and contain minimal distortions and visual noise.
Each invoice contains tabular data, and the dataset itself contains at least 3 different types of layouts, which allows us to test the models across a variety of document designs.
Another important aspect is the year of the document: the dataset includes invoices issues from 1971 to 2020, allowing us to see how well modern AI services handle older document formats.
AI Services Compared: Quick Profiles
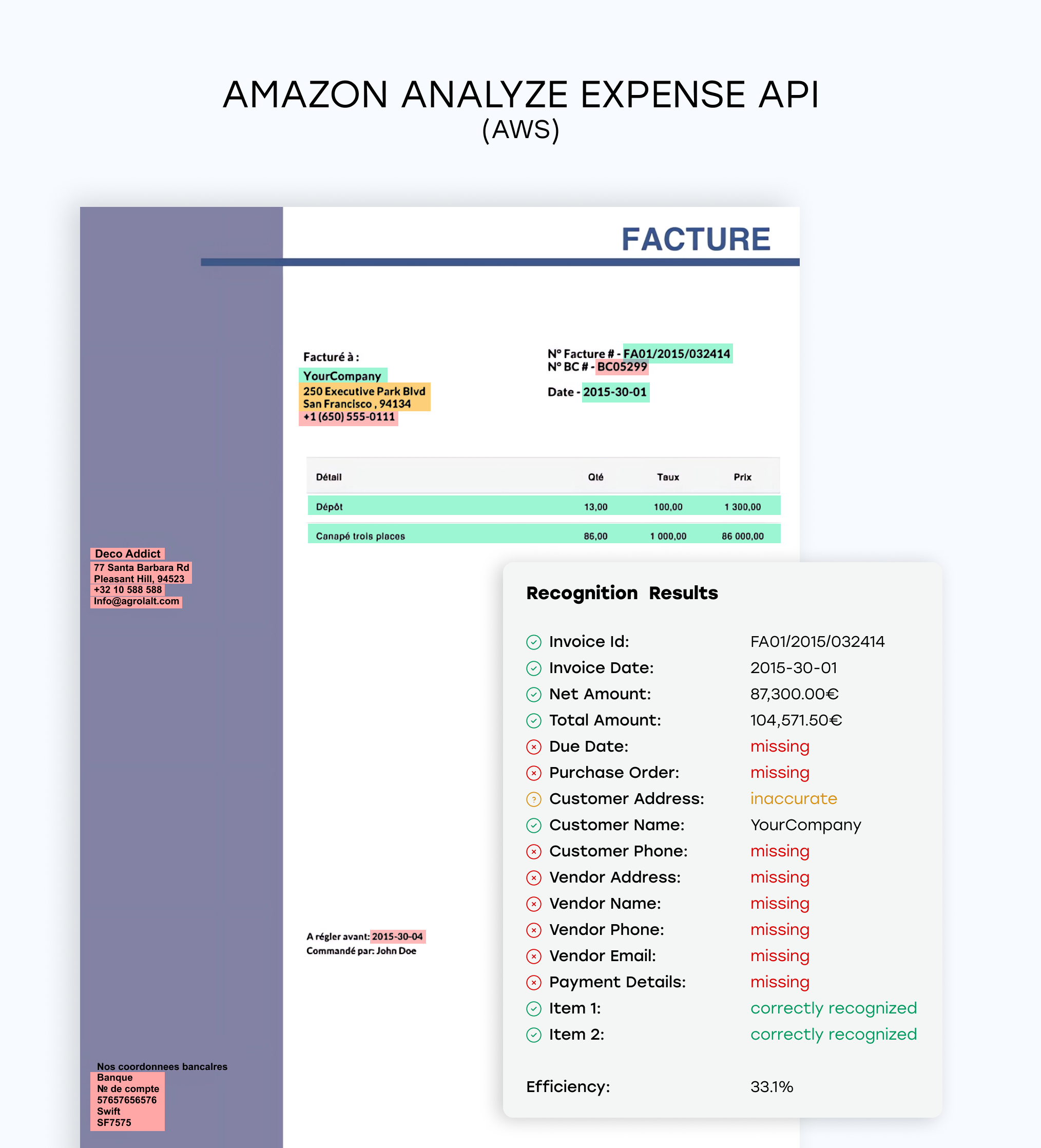
Amazon Textract (AnalyzeExpense)
Approach: Pretrained invoice parser via AWS AnalyzeExpense API
Strengths: Fast, scalable, and reliable on basic fields like totals and vendor names
Weaknesses: Moderate field accuracy; struggles with complex layouts and table parsing
Best For: High-volume, low-complexity invoice workflows where speed is more critical than depth
Google Document AI (Invoice Parser)
Approach: Prebuilt invoice model within Google Cloud’s Document AI suite
Strengths: Easy GCP integration; quick setup through the Google Console
Weaknesses: Weakest overall performance in both field and line-item accuracy; especially limited on complex or older invoices
Best For: Basic GCP-native workflows involving simple invoice formats
Azure Document Intelligence
Approach: Layout-aware, pretrained model with strong semantic parsing from Microsoft Azure
Strengths: Excellent at handling non-standard layouts, nested tables, and complex invoice structures; second-best overall field and table accuracy
Weaknesses: Slightly slower than AWS; occasional field gaps in edge cases
Best For: Semi-structured to complex invoices, particularly those with tables or older formats
GPT-4o + OCR (GPTt)
Approach: Combines external OCR (e.g. Azure Read or Tesseract) with GPT-4o for extraction and reasoning
Strengths: Highest field-level accuracy (98%); excellent with layout variance and handwritten or non-standard formats
Weaknesses: Slower processing (~16s per page); requires additional OCR integration and setup
Best For: High-accuracy workflows involving complex documents and business-critical data extraction
GPT-4o (Image Input) (GPTi)
Approach: Direct image input using GPT-4o’s multimodal capabilities (no separate OCR)
Strengths: Simple to deploy; low integration effort; strong field accuracy (90.5%)
Weaknesses: Weak on table/line-item extraction; slowest option (~33s per page)
Best For: Lightweight, internal automations, R&D tasks, and scenarios where table parsing is not essential
AWS Textract vs Google Document AI (Vision)
When evaluating AI services for invoice processing, two of the most widely known providers are Amazon Textract and Google Document AI (formerly based on Google Vision APIs). Both offer pretrained models for structured document extraction — but how do they compare in practice?
Our updated tests reveal a significant performance gap, especially in terms of accuracy and handling of itemized tables.
Accuracy
We tested each tool on a broad set of real-world invoices, both modern and historical. Amazon Textract, using its AnalyzeExpense API, delivered modest results on standard fields such as invoice totals, dates, and vendor names. It consistently extracted key-value pairs, but showed limitations with nested data and tables.
Google Document AI’s Invoice Parser, on the other hand, underperformed in nearly all areas. It frequently missed line items and showed inconsistency in extracting totals and labels — particularly on multi-column or non-standard layouts, where it struggled more than Textract.
However, benchmark data shows that both AWS and Google trail significantly behind newer and more capable tools:
- Textract field accuracy: ~78%
- Google Document AI field accuracy: ~82% (slightly better than AWS, but poor table handling drags down its utility)
- Line-item detection: Textract: 82% > Google: 40% (large gap in structured data parsing)
While Google slightly outperformed Textract in field-level accuracy, its inability to reliably extract line items makes Textract the better option between the two.
Speed & Cost
Both services are cloud-native and fast, typically processing a page in under 4 seconds.
- Cost: Comparable — ~$10 per 1,000 pages for both
- Speed: Similar — average latency per page is 2–4 seconds
There’s no meaningful difference in cost-effectiveness, but Google’s lower performance makes Textract a better value overall.
Ease of Use
- Textract: Well-documented API, consistent JSON outputs, and reliable field labeling.
- Google Document AI: More user-friendly UI via GCP Console, but unpredictable outputs and weaker table extraction.
Both services integrate well into their respective cloud platforms, so existing infrastructure and tooling can also influence the decision.
Bottom Line
If you're choosing between AWS Textract and Google Document AI for invoice processing, Textract comes out ahead in our evaluation. While neither tool excels at complex document handling, Textract offers better overall reliability, especially for structured data and itemized tables.
That said, both lag behind newer entrants like Azure AI Document Intelligence and GPT-4o API, which showed significantly better performance in recent benchmarks.
Azure Document Intelligence vs AWS Textract
When comparing invoice recognition tools, Microsoft’s Azure Document Intelligence and Amazon Textract are two of the strongest traditional cloud options. Both offer pretrained APIs tailored for structured documents and integrate well within their cloud ecosystems. But their performance diverges when handling complex layouts, tables, and extraction consistency.
Our benchmarking showed Azure slightly outperforming AWS in key areas — particularly when dealing with irregular or older invoices.
Accuracy
Azure and Textract both scored similarly in overall field recognition (~78–93% depending on document type), but Azure held a clear lead in parsing complex layouts and extracting line items:
- Field Accuracy: Azure: 93%, AWS: 78%
- Line-item detection: Azure: 87% > Textract: 82%
- Layout handling: Azure excelled at multi-column and nested tables
Textract remains strong on templated fields, but Azure’s superior structure awareness makes it more versatile on real-world invoice formats — especially those created before 2000.
Speed & Cost
- Pricing: Both are similar — ~$10 per 1,000 pages
- Speed: Textract slightly faster (~2.5s/page vs Azure’s ~3.2s/page), but the difference is negligible
Both platforms are production-grade, cloud-native, and offer strong service-level agreements.
Ease of Use
- Textract: Predictable and clean key-value output, but limited semantic parsing.
- Azure Document Intelligence: Richer semantic output, more robust table handling, and layout maps with confidence scores — useful for custom validation layers.
Azure’s more detailed output structure supports deeper integration for invoice workflows that require validation or enrichment logic.
Bottom Line
If you're working with simple or template-based invoices, AWS Textract remains a reliable and efficient option. But if your invoice formats are variable or require accurate line-item recognition and layout parsing, Azure Document Intelligence is the stronger choice — particularly on historical or non-standard documents.
For teams looking for an alternative to AWS with better document structure awareness, Azure is currently the top performer among traditional cloud providers.
Automated Invoice Processing Results (2025)
To evaluate the real-world capabilities of AWS Textract and its alternatives, we benchmarked five leading document recognition models across a diverse set of invoice samples. These invoices varied in format, layout complexity, and age — simulating realistic enterprise use cases.
Each tool was evaluated across three critical dimensions:
- Field-Level Accuracy (totals, dates, vendor names, etc.)
- Line-Item Extraction (goods/services listed in invoice tables)
- Processing Time and Cost
1. Field-Level Accuracy
We assessed each tool's ability to extract structured fields like invoice totals, tax amounts, payment due dates, and vendor names. Accuracy was based on how well each model’s output matched human-verified ground truth values.
|
Model |
Field Accuracy (%) |
|---|---|
|
GPT-4o + OCR (GPTt) |
98.0% |
|
Azure Document Intelligence |
93.0% |
|
GPT-4o (Image Input) |
90.5% |
|
Google Document AI |
82.0% |
|
AWS Textract |
78.0% |
- Winner: GPT-4o + OCR (GPTt), with the highest accuracy across all structured fields
- Azure outperformed AWS and handled complex formats more effectively
- Google Document AI trailed in accuracy, especially on older or non-standard invoices
2. Line-Item Extraction
Capturing individual products and services from invoice tables is critical but difficult. We measured extraction performance by evaluating table structure completeness, accuracy of line entries, and alignment with ground truth.
|
Model |
Line-Item Score (%) |
|---|---|
|
Azure Document Intelligence |
87.0% |
|
AWS Textract |
82.0% |
|
GPT-4o (Image Input) |
63.0% |
|
GPT-4o + OCR (GPTt) |
57.0% |
|
Google Document AI |
40.0% |
- Azure was the top performer, consistently extracting tables across diverse layouts
- Textract also performed well, especially on clean invoice templates
- GPT-4o-based models struggled with structured tables despite excellent field accuracy
- Google Document AI underperformed, often failing to parse multi-column tables
3. Speed and Cost
To assess efficiency, we benchmarked each tool on a standardized invoice set to calculate average latency and projected API cost per 1,000 pages.
|
Model |
Processing duration per page, s |
Cost, per 1000 pages |
|---|---|---|
|
AWS Textract |
2.9 ± 0.2 |
$101 |
|
Google Document AI |
3.8 ± 0.2 |
$10 |
|
Azure Document Intelligence |
4.3 ± 0.2 |
$10 |
|
GPT-4o (Image Input) |
16.9 ± 1.9 |
$8.80 |
|
GPT-4o + OCR (GPTt) |
33.0 ± 2.3 |
$8.80 |
Notes
1 — $0.008 per page after one million per month
- Cloud-native tools (AWS, Azure, Google) were much faster for high-volume use
- GPT-4o-based options were slower but yielded better accuracy — especially for field data
- Cost differences were minimal across all services; performance is the real differentiator
Best Alternatives to Amazon Textract in 2025
While Amazon Textract offers a reliable foundation for invoice data extraction, our 2025 benchmark testing shows that several alternatives now outperform it — depending on your accuracy needs, document complexity, and system architecture.
Below are the top-performing alternatives based on our evaluation:
1. GPT-4o + OCR (GPTt)
Best Overall Field Accuracy & Flexibility
If you're looking for the most accurate alternative to AWS Textract, GPT-4o paired with a third-party OCR layer (such as Azure Read or Tesseract) delivered the highest field-level accuracy in our tests. It handled complex layouts, inconsistent formats, and edge cases with exceptional precision. While it doesn't lead in table parsing, its raw field recognition was unmatched.
- Highest field accuracy in the benchmark (98%)
- Extremely adaptable to edge cases and layout variance
- Table recognition is solid but trails Azure
- Significantly slower (16+ seconds per page), with more integration effort required
Ideal For: Complex documents, diverse invoice formats, and post-processing pipelines where field accuracy is paramount.
2. Azure Document Intelligence
Best Cloud-Native Replacement for Textract
Azure’s pretrained Document Intelligence model clearly outperformed AWS Textract in our tests. It offered stronger accuracy on both standard fields and complex layouts — including multi-column tables and nested structures. Its structured output and robust layout interpretation make it well-suited for production systems.
- Field accuracy: 93% vs AWS’s 78%
- Best-in-class table and line-item detection (87%)
- Strong layout handling across document variations
- Pricing and speed comparable to Textract (2–4s per page)
Ideal For: Teams in the Microsoft ecosystem or those processing invoices with variable or complex layouts.
3. GPT-4o (Image Input)
Best for Quick Prototyping and Lightweight Use Cases
GPT-4o with direct image input (no third-party OCR) is easy to use and more accurate than AWS Textract for field extraction — scoring 90.5% in our tests. While it falls short in table parsing and processing speed, it offers a low-barrier entry point for R&D or internal automation efforts.
- No separate OCR integration needed
- Higher field accuracy than Textract
- Table extraction weaker; not production-ready for detailed line-item work
- Slow (~33 seconds per page), not ideal for high-volume use
Ideal For: Low-risk scenarios, prototypes, and internal tools where ease of use is prioritized over throughput.
Not Recommended: Google Document AI (Invoice Parser)
Google's Invoice Parser model showed the weakest performance in nearly every category. It consistently missed key fields and failed to handle structured tables, especially in older or irregular invoices. While GCP integration is smooth, the model is not suitable for production invoice workflows without significant manual correction.
- Lowest line-item accuracy (40%)
- Inconsistent totals and vendor field extraction
- Slightly better than AWS Textract for modern invoice templates, but still limited
Only viable for: Very simple invoices and low-risk use cases within the GCP ecosystem.
See How Top AI Document Tools Stack Up
Choosing the Right Alternative
When selecting an AWS Textract alternative, the right tool depends on your priorities:
|
Priority |
Recommended Tool |
|---|---|
|
Maximum field accuracy |
GPT-4o + OCR (GPTt) |
|
Best table and layout handling |
Azure Document Intelligence |
|
Low setup complexity |
GPT-4o (Image Input) |
|
Cloud-native replacement |
Azure Document Intelligence |
Whether you're migrating from Textract or evaluating invoice extraction tools for the first time, these alternatives represent a meaningful step forward in performance and capability — each suited to different needs across speed, structure, and scalability.
Invoice Recognition Results: Detection Comparison


Conclusion
- The most effective services for detecting invoice fields are Azure AI Document Intelligence and GPT-4o API with 3rd party OCR, with Azure being more efficient at processing older invoices (created before 2000) and extracting essential fields, and GPT-4o being more effective at processing modern invoices (created after 2000) and extracting all fields,
- Google Document AI - Invoice Parser shows the worst recognition results in almost every test, except for processing newer invoices where AWS shows the weakest detection accuracy results,
- All AI services are similar in cost: $10 per 1000 invoices,
- GPT-4o and GPT-4o using 3rd party OCR are the slowest by far: 33 and 16 seconds per page respectively, while AWS, Azure and Google show similar processing duration of 2 to 4 seconds per page,
- The maximum extraction quality of an out-of-the-box invoice processing solution is 97% shown by GPT-4o API with 3rd party OCR. These results include newer invoices only,
- Modern AI services show decent results of extracting data from invoices without fine tuning, however none of them can be used in a real invoice processing system without extra configurations, as recognition results are either limited to a short list of fields or very low in quality. However, GPT-4o API with 3rd party OCR and Azure AI Document Intelligence are the most promising.