In today's digital age, the ability to efficiently process and analyze documents is critical for businesses seeking to maintain a competitive edge. As the volume of data continues to grow, Intelligent Document Processing (IDP) solutions have become essential tools for automating document-centric workflows.
Among the leading technologies in this space are Azure Document Intelligence and AWS Textract. In this article we aim to explore what these services offer and how they compare to custom, “from the ground up” document processing software.
With the rise of big data, businesses are inundated with vast amounts of information that need to be accurately and swiftly processed. IDP solutions offer significant advantages, like reducing manual effort, minimizing errors, and accelerating decision-making processes. As a result, choosing the right IDP solution is crucial for optimizing operational efficiency and ensuring data-driven success.
This comparative analysis aims to equip business owners with the knowledge needed to evaluate these IDP solutions effectively. By examining the key aspects of Azure Document Intelligence, AWS Textract, and custom solutions, we aim to guide you in selecting the most suitable approach for your business, ultimately enhancing productivity and driving growth.
Looking for a software development team?
Describe your project and we will come back with a time and cost estimation
Data Extraction From Tax Forms
In this article we will use tax forms for testing document processing solutions as tax documents are complex enough to highlight how each IDP solution handles data extraction challenges.
Tax documents essentially present information in a structured way, akin to a map, with fields or "keys" associated with corresponding values. For example, let's examine the sample provided by the Intuit ProSeries Tax Organizer:

Although humans can easily interpret this, computers have difficulty extracting the information. So we need a data format more like this:
|
"Year": { |
OCR tools extract text directly from images, which is a fundamental step in understanding the content of a document. However, it is not enough.
Key-value mapping is more complex and difficult to implement. Intuit ProSeries Tax Organizer demo shows why:



Some values do not have corresponding keys, while others may have multiple keys due to the structure of the table, where row and column labels define the field despite their spatial separation on the page.
Associating keys with values involves subjective interpretation of page layout, punctuation, and stylistic cues. Key-value pairs can be represented vertically or horizontally, with keys highlighted in various ways, such as colons or bold font.
If your documents are interactive and have the ability to dynamically fill fields, then another important requirement in the data extraction service is working with fillable fields.
There are some off-the-shelf OCR solutions, as well as solutions that allow you to extract key-value pairs from a document. In this article we will examine two most popular intelligent document processing services: AWS Textract and Azure Document Intelligence.
AWS Textract: Pros and Cons
Textract, an integral component of Amazon Web Services (AWS), stands as a prominent offering within the realm of major cloud providers. Given the vast amounts of data Amazon has access to, their document recognition AI is quite powerful and is able to process reasonably complex documents.
Despite its widespread use in intelligent document processing systems, there are significant drawbacks to using AWS Textract:
- PDF files are only supported by asynchronous operations; synchronous and asynchronous operations support JPEG, PNG, and TIFF files. Size limits are much higher for asynchronous operations (500MB and 3,000 pages for PDF and TIFF files) than for synchronous operations (10MB, 1 page)
- Amazon Textract supports up to 15 queries per page for synchronous operations and up to 30 queries per page for asynchronous operations
- Cannot classify documents by document type (Passport, Tax Return, Form 1040, Schedule, etc.)
- AWS Textract uses a standard model to extract data from your specific forms. You don't have the ability to further improve and refine the generalized model for your specific form or task.
- Does not extract data from fillable fields.
To initiate asynchronous calls with Textract, documents must be first uploaded to an S3 bucket; direct submission to Textract is not possible. If your data is already stored in S3, this requirement may not pose any noticeable inconvenience. However, if your data is not already in S3, this step may take significant additional time.
Interested in AWS projects?
We are a reliable cloud development partner with 20+ years of experience
Pricing
- Detect Document Text API (OCR): $0.60-$1.50* per 1,000 Pages
- Forms: $40.00-$50.00* per 1,000 Pages
- Tables + Forms: $10.00+$40.00-$15.00 + $50.00* per 1,000 Pages
* [Over 1 million pages in a month]-[First million pages in a month]
Detect Document Text API uses OCR technology to extract text and handwriting from a document.
Analyze Document API for Forms extracts data such as key-value pairs (“First Name” and associated value, such as “Jane Smith”). It also uses OCR technology to extract all the text and handwriting from a document.
Analyze Document API for Tables extracts tabular or table data organized in columns and rows. It also uses OCR technology to extract all the text and handwriting from a document.
Azure Document Intelligence: Pros and Cons
AI Document Intelligence is an AI service that applies advanced machine learning to extract text, key-value pairs, tables, and structures from documents automatically and accurately. You can start with pre-built models, or create your own models tailored to your documents, either locally or in the cloud, using the AI Document Intelligence Studio or SDK.
To extract data with high quality, you need to train your own model using the Azure Document Intelligence toolkit. Training custom models is always free with Document Intelligence. You are only charged when a model is used to analyze a document.
There are significant drawbacks when using Azure Document Intelligence for extracting data from complex documents:
- Microsoft has a pre-built model for generic form extraction, but the quality of work of this model is very questionable for forms outside the list of prebuilt forms. So if you want to get form data out of a document that’s not an English-language receipt, invoice, ID, or business card, you must train a custom model.
- There is no general-purpose fully off-the-shelf service to extract key-value pairs.
- Maximum amount of custom ML models trained per month: 20
- For PDF and TIFF, up to 2000 pages can be processed (with a free tier subscription, only the first two pages are processed).
- Does not extract data from fillable fields.
Pricing
- Read (OCR): $0.60-$1.50* per 1,000 Pages
- All Prebuilt Models:: $10.00 per 1,000 Pages
- Custom extraction : $50.00 per 1,000 Pages
* [Over 1 million pages in a month]-[First million pages in a month]
Read: Extract printed and handwritten text along with barcodes, formulas and font styles from images and documents.
All Prebuilt Models: Extract structured data (tables, key-value pairs) from unique document types using the following prebuilt models: Invoices, Receipts, Passports and Identity documents, US Health insurance cards, US Tax W-2, US Tax 1040, US Tax 1098, US Tax 1099, US Mortgage 1003, US Mortgage 1008, US Mortgage closing disclosure, Marriage certificates, Credit cards, Contracts, Business cards .
Custom extraction: Train custom models to classify documents and extract text, structure and fields from your forms or documents. You can label and build a custom model to extract a specific schema (tables, key-value pairs) from your forms and documents.
Custom Solution vs Off The Shelf Cloud Services
Given the drawbacks of the two most popular document processing tools, many businesses look for custom IDP solutions to perform smart document analysis and data extraction. Tailor-made document processing software is not only highly customizable, but is significantly more cost effective: even though off the shelf cloud services don't require an initial investment, the monthly cost of processing hundreds of documents quickly adds up and results in higher costs when compared to a custom solution.
We at Businessware Technologies have created our very own smart document processing system which is used as the basis for our IDP projects with additional fine-tuning. We call it Ripper — a custom-made complex document processing solution for extracting both structured and unstructured data.
Ripper Service Features
Ripper service accepts a PDF document as input, and as output it returns a JSON file with extracted values and coordinates of bounding boxes of target fields in key-value format:
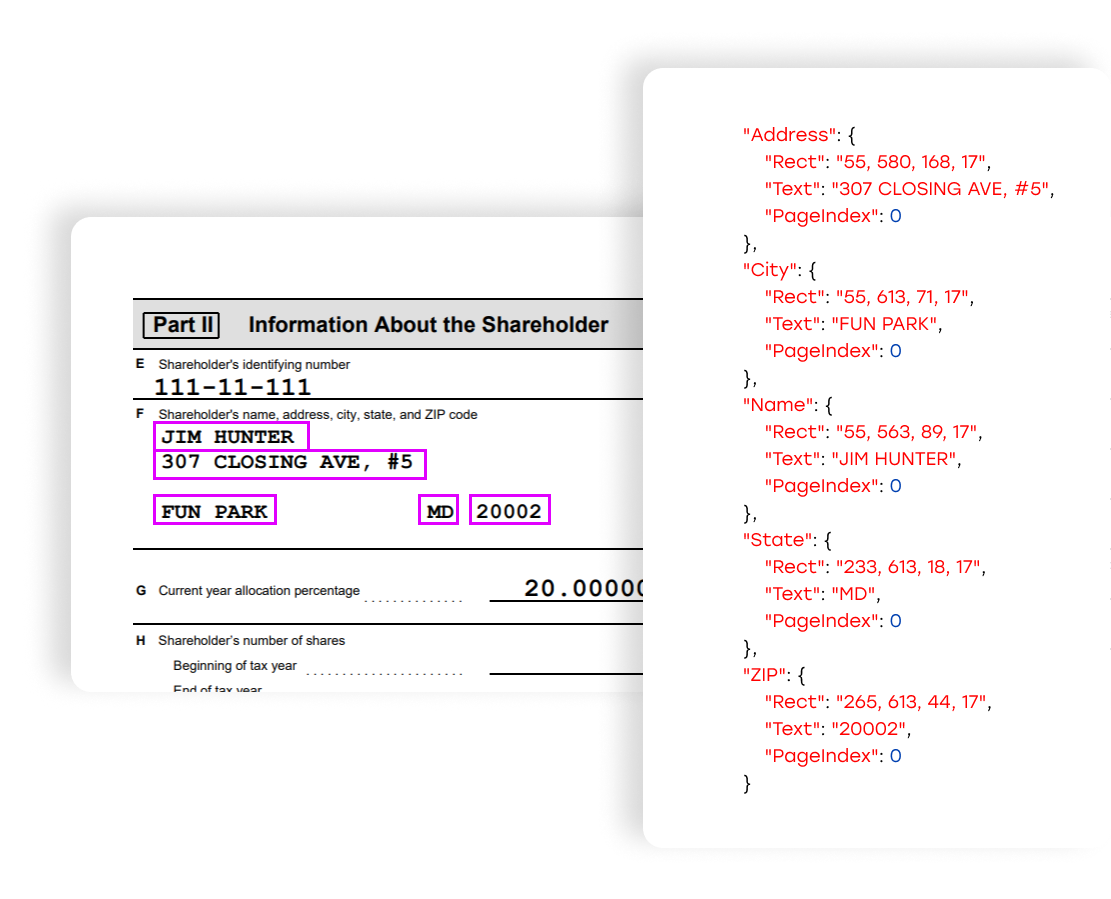
The Ripper Service philosophy is to treat each form individually. The capabilities of the Ripper service allow fine tuning and a custom approach to any complex document as well as handling document fillable fields.
We utilize top-tier AI technologies to achieve a high degree of accuracy, vast functionality and system flexibility. For example, we use OpenAI to process visual information in real time, multiple SDKs to compose, display, capture, annotate, clean-up, edit and print PDF documents and images, and AI models to extract text.
Ripper Service processes data in multiple stages:
- First, the service finds all geometric objects, like vertical and horizontal lines and table cells, on a given page,
- Second, the service extracts text from the page with the coordinates of the bounding boxes,
- Next, it determines document type using the information from the 1st and 2nd steps (Tax return, Voucher, Identity document, payment receipt etc.),
- Last, the service mapps out and extracts target fields, using the relative coordinates of words and geometric objects on the page.
Reaper Service limitations:
- Each form requires developing its own detector,
- If a document does not contain a text layer, then the service needs to use a paid OCR service. This leads to corresponding quotas and limits.
Pricing
- Paid OCR service (if needed): $0.60-$1.50* per 1,000 pages,
- Document processing:
- Single Server or Single Application: $995
- Scalable solution(any number of servers, e.g. Kubernetes, AWS Lambdas etc.): $3295
* [Over 1 million pages in a month]-[First million pages in a month]
The Ripper service offers great opportunities for processing large and small multi-page documents with a complex structure and layout that require an individual approach. The price of use per page of this service is much more affordable compared to the cloud solutions offered by Azure and AWS.
How much will your project cost?
Order an initial consultation and get an accurate cost estimation and project roadmap
Comparison Of Service Performance Results
To compare the performance of all three services, ProSeries Tax organizer was used as an example.
Performance Over Time (Mean)
|
BWT Ripper Service (100 DPI) |
AWS Textract |
Azure Document Intelligence |
|
|
1 page document |
8 seconds |
53 seconds |
13 seconds |
|
66 page document |
18 seconds |
99 seconds |
47 seconds |
ROI
Pricing example 1: Total pages processed = 10,000 (Price per 1,000 pages)
- Ripper Service (Single Server or Single Application) : $99.50
- Ripper Service (Single Server or Single Application + OCR) : $101.00
- Ripper Service (Scalable solution) : $329.50
- Ripper Service (Scalable solution + OCR) : $331.00
- AWS Textract: $65.00
- Azure Document Intelligence : $50.00
Pricing example 2: Total pages processed = 100,000 (Price per 1,000 pages)
- Ripper Service (Single Server or Single Application) : $9.95
- Ripper Service (Single Server or Single Application + OCR) : $11.45
- Ripper Service (Scalable solution) : $32.95
- Ripper Service (Scalable solution + OCR) : $34.45
- AWS Textract: $65.00
- Ripper Service : $50.00
Pricing example 3: Over 1 million pages (Price per 1,000 pages)
- Ripper Service (Single Server or Single Application) : $0.99 or less
- Ripper Service (Single Server or Single Application + OCR): $2.49-$1.50 / $1.49-$0.50*
- Ripper Service (Scalable solution) : $3.29 or less
- Ripper Service (Scalable solution + OCR) : $4.79-$1.50 / $3.79-$0.50*
- AWS Textract : $65.00 / $50.00*
- Azure Document Intelligence: $50.00
* Over 1 million pages total / in a month
Any pricing doesn't include customization for specific forms and hosting/infrastructure costs. Total charge depends on the number of forms, loads, peak loads, cloud/in-house deployment, etc.
Results Of Extracting Key-value Pairs From Forms
Azure Document Intelligence
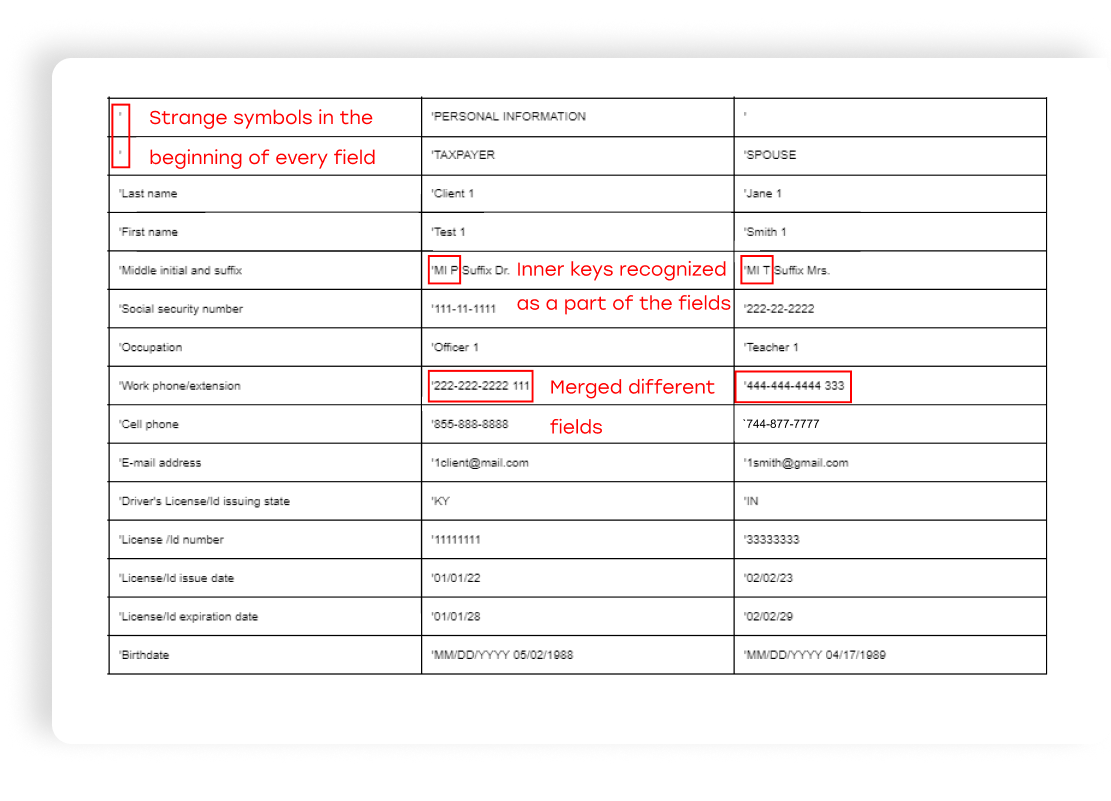
Azure Document Intelligence general model missed a significant amount of key-value pairs and made many mistakes in the found fields in the Personal Information section.

If we recognize this section as a table, the general model will also make mistakes in the table structure. You need some time to parse and handle this table. But the table may not have a fixed structure for every new request. So it's hard to adapt to your algorithm:
Another option is to train your own custom model for your form. Azure Document Intelligence provides this option, so it could resolve the issues described above.
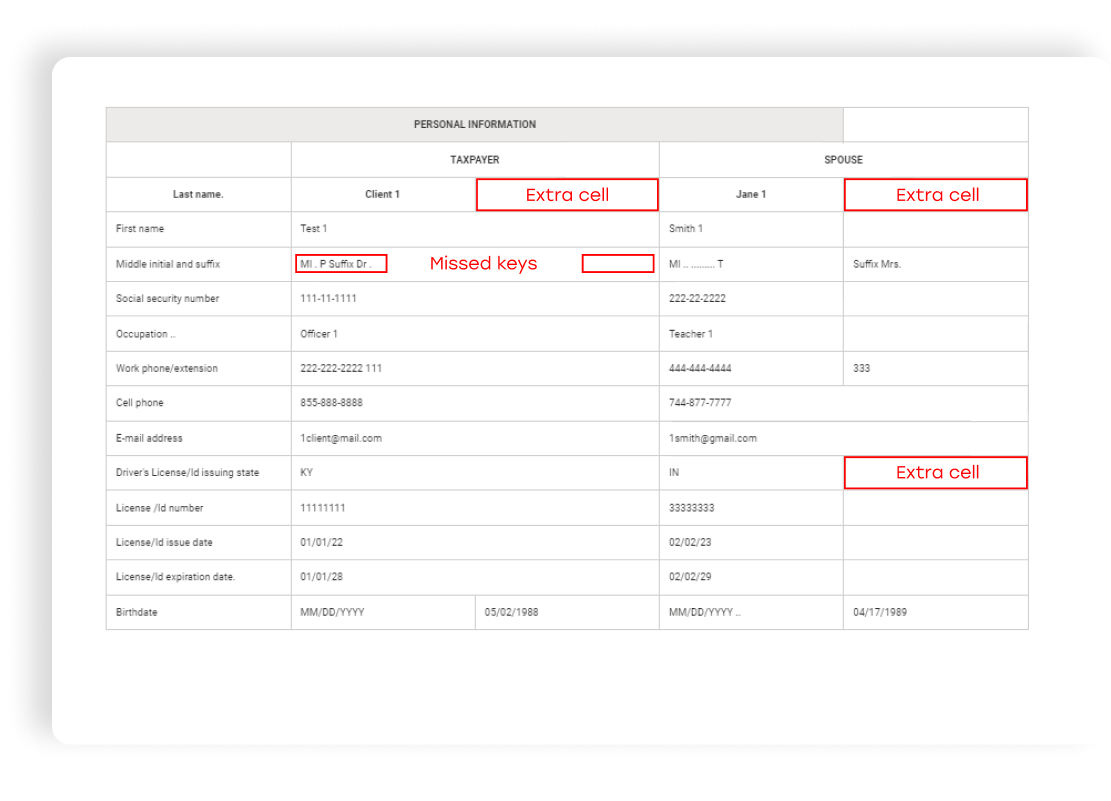
AWS Textract (Forms + Tables)
AWS Textract extracts key-value pairs slightly better than the Azure general model, but it still made a lot of mistakes (lots of missing keys and values, especially in the Spouse column).

If we recognize this section as a table using AWS Textract, some of the fields with multiple keys, or keys with multiple values will be merged into one cell. Therefore, the structure will not be correct.
AWS Textract doesn’t provide the ability to train a custom model like Azure.
Ripper Service
The Ripper Service allows you to fine-tune detectors for each individual form. Consequently, the results will be better than the generalized models of Azure and Amazon.

All the keys and values have been detected and extracted with bounding boxes correctly. It required additional analysis of the document structure and the implementation of a special detector for this section.
Conclusion
Summarizing all of the above, it becomes clear that the solutions described are not universal. Cloud services that provide off-the-shelf solutions are very expensive, costing 5-6.5 cents per page, which may be a problem for commercial use. At the same time, cloud services provide high-quality and inexpensive OCR tools that extract unstructured text, however, they don’t have the ability to extract data from interactive documents with fillable fields.
Azure Document Intelligence has a fairly fast response for a single-page document and scales well as the number of pages increases. Using a general model showed poor quality of key-value pair and table recognition. However, there is an option to additionally train your own model for a specific form, which works quite well. Despite this, it has some limits on the number of models and training samples. There are also pre-trained models for a not very large list of common forms.
AWS Textract has a quite slow asynchronous response, which casts doubt on its use in real-time document processing. In addition, Textract’s form parsing accuracy was poor with some sections of ProSeries Tax organizer. AWS Textract doesn’t have an option to train your custom model or somehow improve the quality of the general model for your specific form.
Ripper Service works quite quickly and can be used to process both single-page and multi-page documents in real time. The quality of extracting key-value pairs and tables is very high, but requires individual adjustments for each unique form. The cost of use per page is significantly lower compared to the cloud services. In addition, the Ripper service can handle interactive documents with fillable fields. However, it requires the use of high-quality OCR (from AWS Textract OCR or Azure Document Intelligence Read) if the original document does not have a text layer.
Why choose Businessware Technologies as your software development company?
- Businessware Technologies is a reliable AI development vendor: it has been recognised as one of the top software development companies by Clutch and Manifest, it is a Top Rated Plus agency Upwork, and has received local awards for its excellent work,
- A team of over 70 highly skilled software engineers with extensive experience in developing complex software for both startups and Fortune 500 companies,
- Deep expertise in modern AI technologies and approaches to system development, like data science, machine learning, OpenCV, Python, Tesseract, and many more,
- Businessware Technologies is a Microsoft Gold Certified partner,
- Businessware Technologies is compliant with GDPR, ISO 9001, ISO 27001 standards,
- Businessware Technologies works with Fortune 500 companies and has had decades-long relationships with most of its clients,
- Businessware Technologies has proven to be a reliable AI outsourcing partner by having an excellent track record in AI and ML development backed by an extensive portfolio of successful projects.
If you have a computer vision project in mind and need help with implementation, contact our manager and they will be happy to help you.