In the ever-evolving landscape of business and technology, data has become the currency of the digital realm. Startups, in particular, are harnessing the power of Artificial Intelligence (AI) to navigate this data-rich terrain and streamline operations. In the realm of accounting, the digitization of documents through AI is revolutionizing the way financial data is processed, managed, and analyzed. Achieving impeccable accuracy in AI document recognition is a mission-critical endeavor.
The accurate recognition of essential information within invoices, receipts, and financial documents is the cornerstone of effective accounting digitization. Errors in document recognition can lead to a cascade of issues, from financial discrepancies to compliance challenges.
The journey to achieving impeccable accuracy, however, is fraught with challenges, particularly for startups with limited in-house resources and AI expertise. This is where the strategic decision to outsource AI development comes into play. In this article, we will embark on a comprehensive exploration of the world of AI document recognition, unveiling techniques to enhance accuracy while shedding light on why outsourcing AI development may be the key to your startup's success.
Looking for AI developers?
We create AI software — and we do it well. Talk to us to get your project started today
Understanding the Significance of Document Recognition Accuracy
The significance of document recognition accuracy cannot be overstated. Accurate recognition of crucial data points within invoices, receipts, and financial documents is the cornerstone of effective accounting digitization. Even minor inaccuracies can have far-reaching consequences, affecting financial stability, compliance, and operational efficiency.
Accurate document recognition plays a pivotal role in the financial health of a business. A recent study published in the Harvard Business Review highlighted this fact, revealing that "Accurate document recognition is the linchpin of successful accounting digitization, with even minor inaccuracies leading to significant operational hurdles."
Financial Discrepancies and the Cost of Inaccuracy
One of the most pressing concerns arising from inaccurate document recognition is the potential for financial discrepancies. Errors in recognizing numerical values, transaction details, or tax calculations can lead to miscalculations that, if left unaddressed, can significantly impact a company's bottom line. Whether it's the misclassification of expenses, misallocated revenues, or incomplete data extraction, these inaccuracies can snowball into substantial financial losses.
In a competitive business landscape, every dollar counts, and accuracy in financial transactions is paramount. The consequences of financial discrepancies can range from budget overruns to erroneous financial reporting. Such errors not only harm the bottom line but can also erode trust among stakeholders.
Navigating Compliance Challenges
Another critical aspect affected by document recognition accuracy is compliance. Tax regulations, financial reporting standards, and industry-specific requirements demand precision in data handling and reporting. Failure to comply can result in penalties, fines, and even legal consequences.
Inaccurate data recognition can lead to compliance breaches, putting your startup at risk. The implications extend beyond financial repercussions; it can damage your startup's reputation and erode trust with clients and regulatory bodies.
The cost of compliance-related fines and penalties due to inaccurate data recognition is significant.
Operational Inefficiencies and Manual Interventions
Beyond financial and compliance aspects, the operational efficiency of a startup is heavily reliant on the accuracy of document recognition. Inaccurate data recognition disrupts workflows, necessitating manual interventions to rectify errors. This not only slows down processes but also increases labor costs.
To address inaccuracies, employees may need to manually review and correct data, diverting their focus from more strategic tasks. Inefficiencies in document recognition can lead to delayed financial reporting, slower decision-making, and missed business opportunities.
The significance of document recognition accuracy in accounting digitization cannot be overstated. Inaccuracies in this crucial area can result in financial discrepancies, compliance challenges, and operational inefficiencies. To achieve success in the world of AI-driven accounting, startups must prioritize accuracy and explore techniques to enhance document recognition.
Outsourcing AI Development for Accounting Document Digitization
As startups endeavor to conquer the world of accounting document digitization, the decision of whether to develop AI capabilities in-house or outsource the task becomes pivotal. While building an in-house team may seem like a tempting proposition, outsourcing AI development offers a host of advantages that can be game-changing for startups in this arena.
Advantages of Outsourcing AI Development
-
Access to Expertise: Outsourcing brings specialized AI expertise to the table. AI development is a complex field that demands a deep understanding of machine learning algorithms, data preprocessing, and model optimization. By partnering with an experienced AI development firm, startups can tap into a reservoir of knowledge and skills that might be challenging to assemble in-house.
-
Cost Efficiency: Building and maintaining an in-house AI team involves substantial costs, including salaries, benefits, infrastructure, and ongoing training. In contrast, outsourcing allows startups to pay for specific AI development services as needed, reducing fixed expenses and improving cost predictability.
-
Rapid Development: Time-to-market is a critical factor for startups. Outsourcing AI development accelerates the process, as experienced teams can quickly prototype, test, and deploy AI solutions. This rapid development can give startups a competitive edge in a fast-moving industry.
Considerations When Choosing an Outsourcing Partner
While outsourcing offers numerous advantages, selecting the right outsourcing partner is essential. Startups should consider the following factors:
-
Expertise and Track Record: Evaluate the outsourcing firm's expertise in AI development and their track record of successful projects. Request case studies and references to gauge their capabilities.
-
Data Security: Given the sensitivity of financial data, robust data security measures are crucial. Ensure that the outsourcing partner follows industry-standard security protocols and compliances.
-
Communication: Effective communication is vital for a successful outsourcing partnership. Choose a partner with clear communication channels and a commitment to transparency.
-
Scalability: As your startup grows, your AI needs may evolve. Select an outsourcing partner capable of scaling their services to meet your changing requirements.
-
Cost Transparency: Establish a clear pricing structure and ensure there are no hidden costs. Understand the payment terms and ensure they align with your budget.
Cost-Efficiency and Time-Saving Benefits
The cost-efficiency and time-saving benefits of outsourcing AI development cannot be overstated. A report by Grand View Research found that businesses that outsourced AI development reported a 30% reduction in development costs and a 40% reduction in time-to-market compared to their in-house counterparts.
By outsourcing, startups can allocate their resources strategically, focus on core business activities, and leverage the expertise of AI specialists, all while accelerating their journey toward accurate accounting document digitization. It's a strategic move that not only enhances competitiveness but also ensures cost-effective and timely AI deployment, a significant advantage in the dynamic landscape of financial technology.
In the next section, we will delve into the specific techniques that can be employed to improve document recognition accuracy, complementing the advantages gained through outsourcing AI development.
AI Document Recognition Accuracy Improvement Techniques
In the quest for impeccable document recognition accuracy, startups exploring accounting document digitization can harness an arsenal of advanced techniques. These techniques are the keys to unlocking the potential of AI-driven recognition systems. Let's delve into some of the most pivotal methods and discuss their relevance to the world of accounting document digitization.
1. Optical Character Recognition (OCR) Enhancements
Optical Character Recognition (OCR) technology has long been a cornerstone of document digitization. Its ability to convert printed or handwritten text into machine-readable text is invaluable for processing invoices, receipts, and financial documents. However, OCR technology has evolved significantly, and startups can enhance its accuracy through various means:
Advanced OCR Engines
Utilizing state-of-the-art OCR engines equipped with deep learning algorithms can significantly improve character recognition accuracy. Modern OCR engines can adapt to various fonts, styles, and languages, making them highly relevant for accounting documents with diverse formats.
Here are a few examples:
-
Google Cloud Vision OCR: Google's OCR engine, part of the Google Cloud Vision AI platform, is known for its accuracy and the ability to handle a wide range of languages and fonts.
-
Tesseract OCR: Originally developed by Google and now maintained by the community, Tesseract is an open-source OCR engine that has seen significant improvements in accuracy and recognition capabilities.
-
ABBYY FineReader: ABBYY's OCR engine is recognized for its exceptional accuracy, especially in handling complex document layouts, tables, and various fonts.
-
Microsoft Azure Computer Vision OCR: Microsoft's OCR engine, integrated into the Azure cloud platform, offers high accuracy and supports multiple languages and formats.
-
Amazon Textract: Amazon's Textract OCR service is designed for extracting text and structured data from documents. It's known for its accuracy in recognizing tables and forms.
-
ABBYY FlexiCapture: ABBYY's FlexiCapture is an advanced OCR and data capture software that offers automation of document processing tasks and supports various languages and formats.
Intelligent Document Processing In Action
We build custom AI document processing systems
Post-Processing Techniques
Implementing post-processing techniques such as spell-checking, language detection, and context-based error correction can refine the accuracy of OCR outputs. This is especially important for documents with intricate financial terminology.
-
Natural Language Processing (NLP): NLP techniques are often used for spell-checking and language detection. NLP models can identify and correct spelling errors and determine the language of the text, which is particularly helpful when dealing with multilingual documents.
-
Contextual Language Models: Advanced language models like BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer) can be employed for context-based error correction. These models have the ability to understand the context of a word or phrase within a sentence, making them effective in identifying and correcting contextual errors.
-
Rule-Based Systems: Rule-based systems are designed to apply specific linguistic rules and patterns to correct errors in text. For example, regular expressions can be used to find and replace patterns of characters that commonly result in OCR errors.
-
Machine Learning-Based Correction Models: Machine learning models, such as sequence-to-sequence models or neural machine translation models, can be trained to identify and correct OCR errors by learning from large datasets of correctly transcribed text.
-
Ensemble Approaches: Combining multiple correction techniques and models into an ensemble approach can often yield superior results. This involves using a combination of rule-based, machine learning-based, and context-aware techniques to correct OCR output.
-
Fuzzy Matching: Fuzzy matching algorithms can be employed to identify and correct OCR errors by comparing recognized text to a dictionary or reference database. This technique is especially useful for handling misspelled words or variations of terms.
-
Contextual Post-Processing Pipelines: Combining several of the above techniques into a pipeline can create a comprehensive approach to post-processing. For example, first, language detection can be used, followed by spell-checking, contextual error correction, and entity recognition.
Document Layout Analysis
OCR engines can benefit from layout analysis algorithms that identify key elements, such as tables, headers, and footers, to improve the organization and accuracy of extracted data.
-
Connected Components Analysis (CCA): CCA is a fundamental layout analysis technique that identifies individual connected components (e.g., characters or line segments) within an image. It can be used to separate text from graphical elements and distinguish different regions of the document.
-
Run-Length Smoothing Algorithm: This algorithm helps in identifying text lines and columns by analyzing run lengths of connected components. It is particularly useful for structured documents like tables.
-
Recursive X-Y Cut: Recursive X-Y Cut is used to divide a document into smaller rectangular blocks by recursively splitting the page horizontally and vertically. This method is effective for extracting tables and other structured content.
-
Zoning Techniques: Zoning algorithms divide a document into zones or regions based on spatial relationships. They can help identify headers, footers, and body content, allowing for better data extraction.
-
Projection Profile Analysis: Projection profile analysis computes histograms of pixel density along horizontal and vertical axes. Peaks and valleys in these profiles can indicate headers, footers, and text blocks.
-
Document Structure Analysis with Graph Theory: Graph-based techniques model the relationships between elements in a document, such as text lines, paragraphs, and tables. Graph theory can help identify hierarchical structures within documents.
-
Table Detection Algorithms: Specialized algorithms for table detection focus on identifying tabular structures within documents, including recognizing rows, columns, and cells. These algorithms are crucial for accurate data extraction from tables.
-
Machine Learning-Based Layout Analysis: Machine learning models, such as convolutional neural networks (CNNs) or deep learning architectures, can be trained to classify different layout elements within documents. These models can adapt to various document layouts and structures.
-
Adaptive Thresholding: Adaptive thresholding techniques can be applied to segment text from the background by adjusting the threshold dynamically based on local image characteristics. This is particularly useful for handling documents with varying backgrounds and contrast.
-
Watershed Transform: The watershed transform can be used to segment images into regions based on the concept of catchment basins. It is effective for separating text from images and other graphical elements.
2. Machine Learning Algorithms
Machine learning (ML) algorithms are at the heart of AI document recognition systems. These algorithms continuously learn from data, enabling them to adapt and improve recognition accuracy over time. For accounting document digitization, ML algorithms play a pivotal role:
-
Supervised Learning: Training ML models with annotated datasets specific to accounting documents helps them recognize patterns, data fields, and formatting, leading to enhanced accuracy.
-
Semi-Supervised and Unsupervised Learning: These approaches are invaluable when dealing with diverse document formats and structures. They allow the system to learn and adapt without exhaustive labeling efforts.
-
Ensemble Learning: Combining multiple ML models can improve accuracy further. Techniques like Random Forests or Gradient Boosting can be employed to achieve robust recognition results.
3. Data Preprocessing and Cleaning
High-quality data is the lifeblood of AI document recognition. Data preprocessing and cleaning techniques are essential for improving accuracy:
-
Noise Reduction: Removing artifacts, such as speckles or smudges, from scanned documents can prevent misinterpretation and enhance recognition accuracy.
-
Image Enhancement: Techniques like contrast adjustment and background subtraction can improve the visibility of text, particularly in low-quality scans.
-
Normalization: Standardizing document formats and layouts can simplify recognition, reducing the risk of errors caused by variations in document structure.
4. Data Augmentation Strategies
Data augmentation strategies involve artificially expanding the training dataset to expose AI models to a wider range of document variations. This is particularly relevant for accounting documents due to their diversity:
-
Synthetic Data Generation: Creating synthetic documents with variations in fonts, styles, and layouts can help models adapt to real-world scenarios.
-
Augmented Labeling: Annotating documents with additional information, such as data field boundaries or language markers, can guide AI models to improve accuracy.
-
Transfer Learning: Leveraging pre-trained models and fine-tuning them for accounting document recognition can save time and resources while maintaining accuracy.
Combining Human Expertise with AI
While AI algorithms and technologies have made significant strides in document recognition accuracy, there remains an indispensable role for human expertise to complement these advancements. The synergy between human intervention and AI is a powerful tool for achieving impeccable accuracy in the realm of accounting document digitization.
Leveraging Human Expertise
In the pursuit of accuracy, human intervention serves as the critical link that enhances the AI-driven recognition process. Here's how human expertise contributes:
-
Data Annotators: Data annotators play a pivotal role in curating training datasets for AI models. Their expertise involves labeling and annotating data, which is essential for training machine learning algorithms effectively. In the context of accounting document digitization, annotators can mark key data points, data field boundaries, and even document-level attributes, ensuring that AI models learn to recognize these elements accurately.
-
Quality Control Experts: Quality control experts oversee the performance of AI recognition systems. They are responsible for verifying the accuracy of AI-generated results, identifying and rectifying errors, and fine-tuning models when necessary. Quality control experts also play a role in developing and refining the post-processing techniques that improve the accuracy of recognized data.
Measuring and Monitoring Accuracy
In the dynamic landscape of AI-driven document recognition for accounting digitization, achieving accuracy is a perpetual journey. Continuous monitoring and improvement of AI accuracy are paramount to ensure that the system performs optimally and meets the rigorous standards of the financial industry.
Importance of Continuous Monitoring
The importance of ongoing accuracy monitoring cannot be overstated. As accounting documents evolve in complexity and diversity, AI models must adapt to stay effective. Continuous monitoring serves several critical purposes:
-
Performance Assessment: Regular evaluation of AI accuracy allows startups to gauge the effectiveness of their recognition systems. It helps identify areas where improvements are needed.
-
Compliance Assurance: In the financial sector, compliance with regulations is of utmost importance. Continuous monitoring ensures that AI systems meet regulatory standards and do not compromise data integrity.
-
Error Detection and Correction: Continuous monitoring enables the early detection of errors and inconsistencies in recognized data. This timely identification allows for rapid corrective action, preventing inaccuracies from propagating.
-
Adaptation to Data Variability: Accounting documents can exhibit substantial variability in formatting and content. Continuous monitoring helps AI models adapt to these variations, maintaining high accuracy across different document types.
Key Performance Indicators (KPIs) and Metrics
To effectively measure and evaluate document recognition accuracy, startups should employ a range of KPIs and metrics tailored to their specific needs:
-
Character Recognition Rate (CRR): This metric assesses the accuracy of text character recognition. A high CRR indicates that the AI system accurately recognizes and interprets characters within documents.
-
Field-Level Accuracy: Evaluating the accuracy of specific data fields within documents, such as invoice numbers, total amounts, and dates, is essential. Field-level accuracy metrics help pinpoint areas that require improvement.
-
False Positive and False Negative Rates: These metrics measure the rate of errors in recognizing data points that are not present (false positives) and missing data points that should be recognized (false negatives). Balancing these rates is crucial for accuracy.
-
Overall Recognition Accuracy: This encompasses the accuracy of the entire document recognition process. It evaluates the system's ability to extract and interpret data accurately from start to finish.
The Role of Feedback Loops
Feedback loops are instrumental in the continuous improvement of AI recognition systems. They create a feedback mechanism between the AI system and human experts, facilitating ongoing learning and refinement:
-
Human Oversight: Quality control experts and data annotators play a pivotal role in identifying and correcting recognition errors. Their feedback guides AI model improvements.
-
Re-Training: Based on feedback, AI models can be re-trained with updated datasets to address specific recognition challenges or patterns identified during monitoring.
-
Algorithm Optimization: Continuous feedback can lead to algorithmic enhancements, improving recognition accuracy over time.
Future-Proofing Your AI Solution
As we navigate the dynamic landscape of AI-driven accounting document recognition, it's crucial to recognize that the field of AI technologies is in a perpetual state of evolution. What's considered cutting-edge today may become obsolete tomorrow. Therefore, future-proofing your AI solution is not merely a strategic choice; it's an imperative for long-term success.
Evolving Landscape of AI Technologies
The field of AI technologies is marked by rapid advancements and breakthroughs. New algorithms, architectures, and techniques emerge regularly, transforming the capabilities of AI systems. For instance, deep learning, neural networks, and natural language processing have revolutionized document recognition accuracy.
Moreover, the integration of AI with other transformative technologies, such as cloud computing, edge computing, and the Internet of Things (IoT), is reshaping the AI landscape. These synergies expand the potential of AI applications, including accounting document digitization.
The Need to Future-Proof AI Solutions
To thrive in this evolving landscape, startups must prioritize future-proofing their AI solutions. Future-proofing involves strategies and actions that ensure an AI system remains relevant and effective in the face of technological shifts. Here's why it's crucial:
-
Sustainable Competitiveness: A future-proof AI solution positions your startup to maintain a competitive edge. As new technologies emerge, you can seamlessly integrate them into your existing AI framework, staying ahead of competitors.
-
Long-Term ROI: Investing in AI development is a substantial commitment. Future-proofing ensures that your investment continues to yield returns over an extended period, mitigating the risk of obsolescence.
-
Scalability: Future-proofing allows your AI solution to scale with your startup's growth. As your operations expand, your AI system can adapt to handle increased data volumes and complexity.
The Role of Ongoing R&D and Updates
Central to future-proofing an AI solution is a commitment to ongoing research and development (R&D) and regular updates. This entails:
-
Monitoring Technological Trends: Staying abreast of emerging AI technologies and trends is fundamental. Regularly assess how new developments can enhance your AI system's performance and accuracy.
-
Adaptive Algorithms: Design AI algorithms and models with adaptability in mind. They should be capable of accommodating new data types, formats, and patterns as they arise.
-
Robust Infrastructure: Build a flexible and scalable infrastructure that can accommodate future AI enhancements and integrations.
-
Regular Updates: Implement a schedule for updating AI components, including algorithms, data models, and processing pipelines. These updates should align with the evolving requirements of accounting document digitization.
Case Studies: Intelligent Document Processing Using AI
Case Study 1: Newspaper Digitization System

AI can be used to process hundreds of documents in a short period of time and turn a large collection of paper documents into a digital archive. We have had an opportunity to work on an AI system for digitizing newspapers for a large european document scanning and digitization company aiming to improve and scale their newspaper scanning efforts.
The task of digitizing a newspaper is the most complicated OCR-based one as newspapers have complex layouts with articles spanning across multiple columns, starting and stopping in arbitrary places, often broken up by images and advertisements.
The AI we’ve developed processes newspaper scans and turns them into editable and searchable digital documents:
-
A preprocessing module removes any paper warp caused by old age or moisture damage, removes dust and scratches, and fills in letters and symbols that have faded with time,
-
A content extraction module detects text blocks that belong to the same article across the entire page and compiles them together in a correct order, including headers, subheaders, illustrations, authorship attribution, and any other elements that are part of the same article. For each detected article our system determines its type, like an editorial article, an advertisement, an obituary, etc.,
-
A visual editor shows all relations between article blocks and allows users to manually edit the document, e.g. reassign an item’s article affiliation, change the blocks order, and change article types.

Take a look at our portfolio
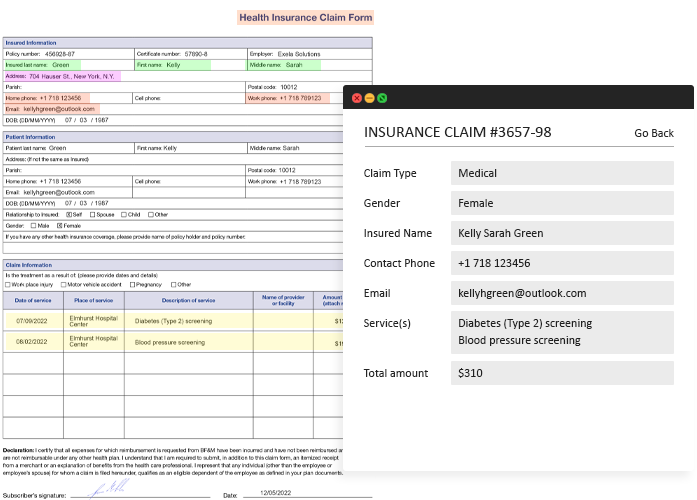
Case Study 2: Data Extraction App For Insurance Claims
The process of manually extracting relevant information from documents is time-consuming and highly error-prone, therefore companies are actively looking for ways of implementing automatic document processing systems to help them reduce the workload and improve data extraction quality.
One of our clients, a medical insurance company, faced challenges with manual insurance claim processing. AI-powered document processing was the perfect fit, so we’ve developed a custom insurance claim processing AI for extracting relevant information from insurance claims.
The app detects claim type (medical, business, etc.) and its layout to improve data extraction and its accuracy. It extracts claim type and title, automating the document identification and digitization efforts. The app also supports batch processing, meaning it can process multiple claims at once.
Our app can work with various claim templates and designs, allowing for seamless data extraction from different claim types. It can work with claims of different designs, including complex formats that span across multiple pages, multiple claim forms on one page, input fields of irregular size and form.
Conclusion
In the realm of accounting document digitization, the pursuit of impeccable accuracy in AI-driven document recognition is the cornerstone of success. As we have explored in this article, startups aiming to disrupt the industry must prioritize accuracy as a non-negotiable imperative. Let's recap the key takeaways:
-
Accuracy is Paramount: Accurate document recognition is the bedrock upon which all subsequent financial processes rely. Inaccuracies can lead to financial discrepancies, compliance issues, and operational inefficiencies.
-
Outsourcing Enhances Success: Outsourcing AI development offers startups a strategic advantage. It provides access to expertise, cost efficiency, and rapid development, allowing startups to compete effectively in the accounting digitization space.
-
Techniques to Improve Accuracy: Advanced techniques, such as OCR enhancements, machine learning algorithms, data preprocessing, and data augmentation, are essential for improving document recognition accuracy. These methods are highly relevant to the accounting document digitization process.
-
Human-AI Collaboration Matters: The synergy between human expertise and AI technology is a powerful tool for enhancing recognition accuracy. Data annotators and quality control experts play pivotal roles in refining AI models for accounting document digitization.
-
Continuous Monitoring and Future-Proofing: Ongoing monitoring and future-proofing of AI solutions are essential. The evolving landscape of AI technologies requires startups to adapt, scale, and update their systems to maintain competitiveness and relevance.
In conclusion, CEOs of startups venturing into the accounting digitization space must recognize the pivotal role of document recognition accuracy. It is the linchpin upon which the success of their endeavors hinges. By leveraging outsourcing advantages, implementing advanced techniques, fostering human-AI collaboration, and committing to ongoing monitoring and future-proofing, startups can achieve the accuracy needed to thrive in this transformative industry. The future of accounting document digitization is within reach, and it begins with a commitment to precision and excellence.