In this analysis, we have analysed 7 popular AI models to test how well they process digital invoices without pre training or any fine tuning.
Read on to learn:
- Which AI model achieves 100% accuracy when extracting items and outperforms all others by 20-65% when processing invoices out-of-the-box,
- Why Google's invoice parser failed our structured data test - and which alternatives delivered reliable results,
- How well modern AI handles low resolution scans.
We regularly benchmark AI models to find the best ones for digital document processing for different applications. Take a look at our previous report where we’ve tested 5 AI models on invoices of various years and a comprehensive report on all of our tests.
IDP Models Benchmark
We are constantly testing large language models for business automation tasks. Check out the latest results.
AI Models For Invoice Processing
This report evaluates and compares the performance of seven distinct methods for invoice recognition across varying years and digitization formats. The focus is on assessing their accuracy in extracting key invoice fields, which is critical for automation and data processing workflows. The following solutions are analyzed:
- Amazon Analyze Expense API (here and below aws)
- Azure AI Document Intelligence - Invoice Prebuilt Model (azure)
- Google Document AI - Invoice Parser (google)
- GPT-4o API - text input with 3rd party OCR (gptt)
- GPT-4o API - image input (gpti)
- Gemini 2.0 Pro Experimental (gemini)
- Deepseek v3 - text input (deepseek-t)
The analysis builds upon previous findings in a February 2025 report to provide an updated and comprehensive comparison.
Invoice Dataset
To ensure a structured and fair evaluation, a standardized dataset of invoices from different years was used. The methodology included:
- Sample Selection: A diverse set of 20 invoices spanning from 2006 to 2020, varying in complexity (number of items, format, and age).
- Field Mapping: A predefined list of 16 key invoice fields was used to compare outputs across all solutions.
- Normalization: For consistency, extracted fields were mapped to a common naming convention (Resulting Field), especially for models like Gemini, Deepseek, and GPT, which were prompted to follow this format.
A collection of scanned and digital invoices was used to test each solution’s ability to handle different formats and years:
|
Invoice Year |
Number of Invoices |
|---|---|
|
2006 — 2010 |
6 |
|
2011 — 2015 |
4 |
|
2016 — 2020 |
10 |
List of Invoice Fields
The following fields were extracted and compared across all models. Each solution uses slightly different naming conventions, which were standardized for evaluation:
|
№ |
Resulting Field |
AWS |
Azure |
|
|---|---|---|---|---|
|
1 |
Invoice Id |
INVOICE_RECEIPT_ID |
InvoiceId |
invoice_id |
|
2 |
Invoice Date |
INVOICE_RECEIPT_DATE |
InvoiceDate |
invoice_date |
|
3 |
Net Amount |
SUBTOTAL |
SubTotal |
net_amount |
|
4 |
Tax Amount |
TAX |
TotalTax |
total_tax_amount |
|
5 |
Total Amount |
TOTAL |
InvoiceTotal |
total_amount |
|
6 |
Due Date |
DUE_DATE |
DueDate |
due_date |
|
7 |
Purchase Order |
PO_NUMBER |
PurchaseOrder |
purchase_order |
|
8 |
Payment Terms |
PAYMENT_TERMS |
- |
payment_terms |
|
9 |
Customer Address |
RECEIVER_ADDRESS |
BillingAddress |
receiver_address |
|
10 |
Customer Name |
RECEIVER_NAME |
CustomerName |
receiver_name |
|
11 |
Vendor Address |
VENDOR_ADDRESS |
VendorAddress |
supplier_address |
|
12 |
Vendor Name |
VENDOR_NAME |
VendorName |
supplier_name |
|
13 |
Item: Description |
ITEM |
Description |
- |
|
14 |
Item: Quantity |
QUANTITY |
Quantity |
- |
|
15 |
Item: Unit Price |
UNIT_PRICE |
UnitPrice |
- |
|
16 |
Item: Amount |
PRICE |
Amount |
- |
Note: For Gemini, Deepseek, and GPT, the models were explicitly instructed to return data in the Resulting Field format for consistency.
Items Detection Comparison
The evaluation of item-level extraction focuses on four key attributes:
- Description
- Quantity
- Unit Price
- Total Price
Note on Google AI: Unlike other solutions, Google’s Document AI does not break down items into individual attributes but returns full item rows as unstructured text, complicating direct comparison for these fields.
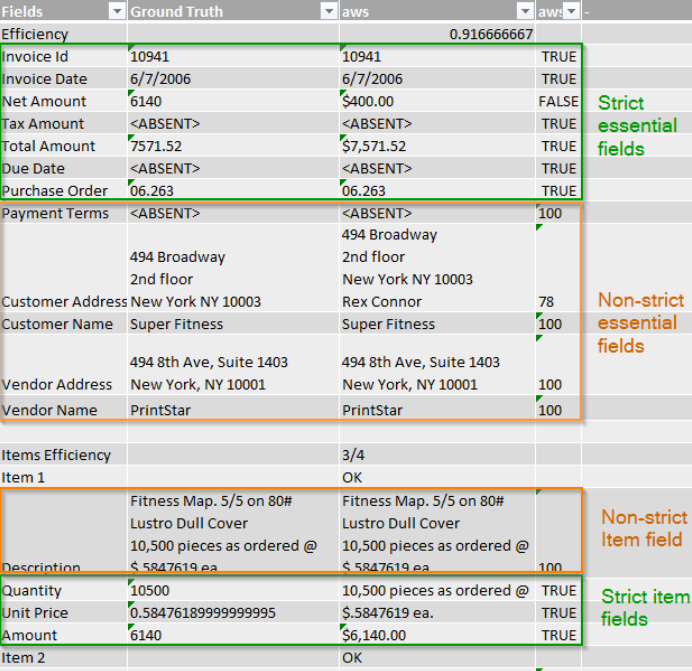
Efficiency Calculation Methodology
To quantify extraction accuracy, a weighted efficiency metric (Eff, %) was applied, combining:
- Strict Essential Fields: Exact matches (e.g., invoice ID, dates).
- Non-Strict Essential Fields: Partial matches allowed if similarity (RLD, %) exceeds a threshold.
- Items: Evaluated as correct only if all item attributes are extracted accurately.
Formulas:
- Overall Efficiency (Eff, %):
Eff, % = (COUNTIF(strict ess. fields, positive) + COUNTIF(non-strict ess. fields, positive if RLD > RLD threshold) + COUNTIF(items, positive)) / ((COUNT(all fields) + COUNT(all items)) * 100
- Relative Levenshtein Distance (RLD, %):
RLD, % = 1 - [Levenshtein distance]/Max(Len(s1),Len(s2)) * 100
- Item-Level Efficiency (Eff-I, %):
Eff-I, % = Positive IF (ALL(Quantity, Unit Price, Amount - positive) AND RLD(Description) > RLD threshold) * 100
Cost Calculation Methodology
Pricing models for AI services were calculated per invoice, accounting for:
- Token-based costs (input/output) for text-based models.
- Image processing costs for vision-enabled models (GPT-4o/Gemini).
Formulas:
- Text-Based Models (GPT/Deepseek + OCR):
[total_cost] = [input token cost] * ([prompt token count] + [OCR input json token count]) + [output token cost] * [result json token count]
- Image-Based Models (GPT/Gemini):
[total_cost] = [input token cost] * ([prompt token count] + [input image token count]) + [output token cost] * [result json token count]
Key Considerations:
- OCR Input Tokens: Generated from third-party OCR output (e.g., AWS Textract).
- Image Tokens: Calculated based on resolution (e.g., GPT-4o’s tokenization for images).
Benchmark: Best LLM For RFQ Data Extraction
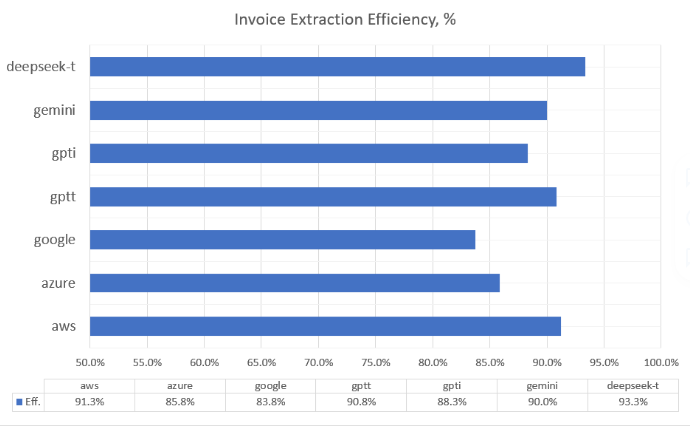
Invoice Recognition Results
Comparison by 12 fields excluding items
Comparison by essential fields and items together
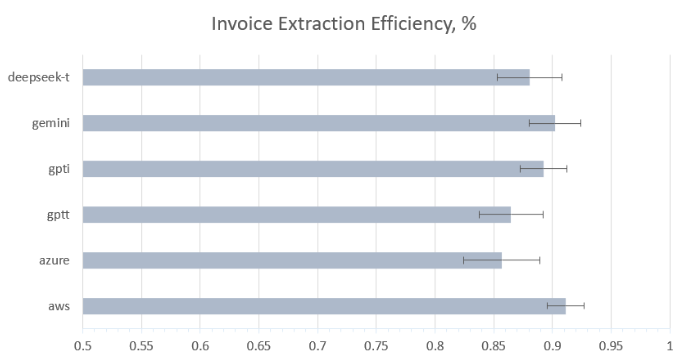

Note: Google AI results were excluded from the charts above.
Key Insights from Invoice Extraction Analysis
Azure’s Limitations with Item Descriptions
Issue: Azure AI failed to detect full employee names in Invoice 5, recognizing only first names instead of complete names.
Impact: This resulted in a significantly lower efficiency score (33.3%) for Azure on this invoice, while other models achieved 100% accuracy across all 12 items.
Conclusion: Azure’s inability to parse multi-word descriptions in structured fields highlights a critical limitation compared to competitors.

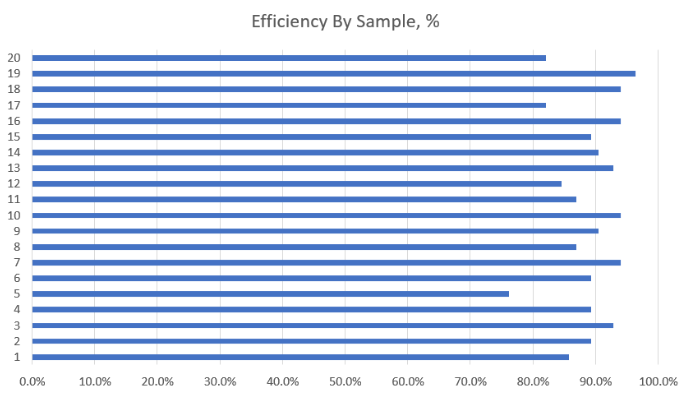
Impact of Low Resolution on Detection Quality
Observation: Low-resolution invoices (e.g., Samples 13, 17, 18) generally did not degrade detection accuracy across models.
Minor Exceptions: Invoice 15: Deepseek misread a comma as a dot, leading to an incorrect numerical value.
Conclusion: Modern OCR and AI models are robust to resolution issues, though rare formatting errors may occur.


Google’s Item Extraction Limitations
Critical Flaw: Google Document AI combines all item attributes into a single unstructured string, making field-level comparison impossible.
Example:
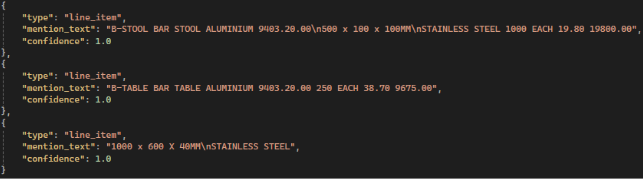
Actual image:

All other services have 100% correct detection with breakdown by attributes:
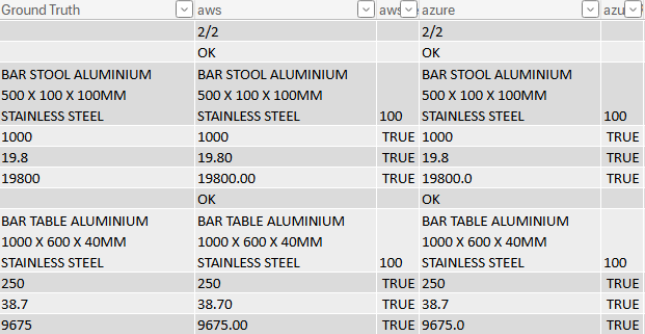
Impact: Google’s approach fails to align with industry-standard attribute breakdowns (Description, Quantity, Unit Price, Amount), rendering it incompatible for automated workflows requiring structured data.
Multi-Line Item Descriptions
Finding: Multi-line item descriptions had no negative impact on detection quality—except for Google AI, which struggles with any structured parsing.
Why It Matters: Complex invoices with wrapped text or line breaks were handled flawlessly by AWS, Azure, GPT, Gemini, and Deepseek.
Excluded samples
Two invoices were excluded due to atypical structures that caused widespread detection failures:
- Missing Extended Amount/Qty Fields: Some models skipped items lacking these fields, disrupting order and omitting ~50% of entries.
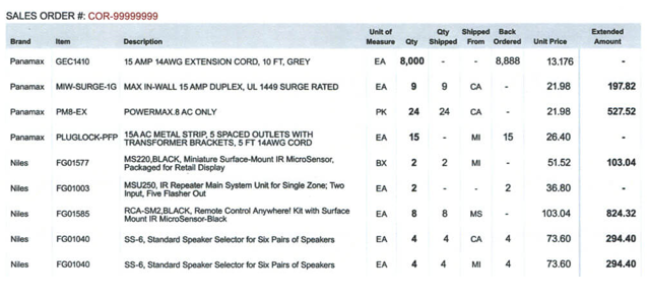
- Sub-Item Recognition Failure: Most services captured only top-level items, ignoring sub-items (e.g., 1.00 lb @ $5.00/lb without clear Quantity/Price).

Insight: Unconventional layouts remain a challenge for all models.
Gemini’s Superior Detailing Capability
Strengths:
- Extracts all fields (not just the standard 4 attributes) when prompted for tabular output.
- Highest accuracy in preserving text and numerical values (see Sample 20 comparison below).
Comparison (Sample 20):
|
Model |
Accuracy of Attributes |
Notes |
|---|---|---|
|
Gemini |
100% |
Correct values and formatting. |
|
GPT-4o |
Partial |
Inaccurate numerical values. |
|
Deepseek |
Low |
Missing/incorrect fields. |
Example: Sample #20, actual image:

Gemini:
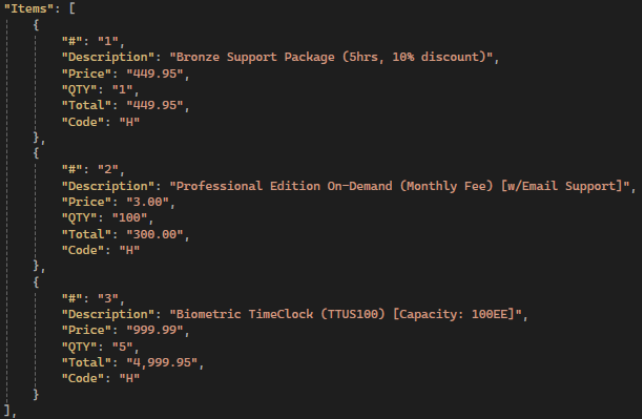
GPTI: Same attributes but inaccurate values:
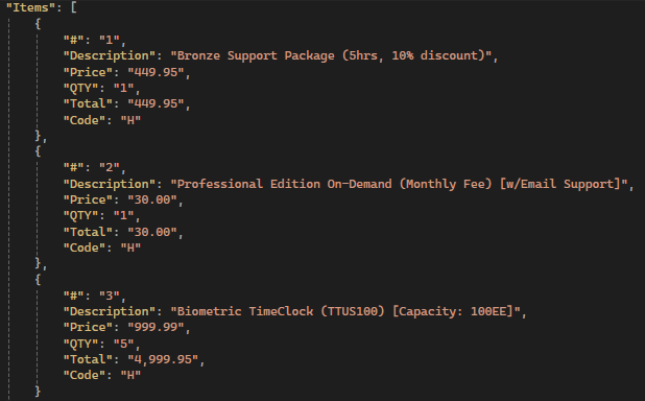
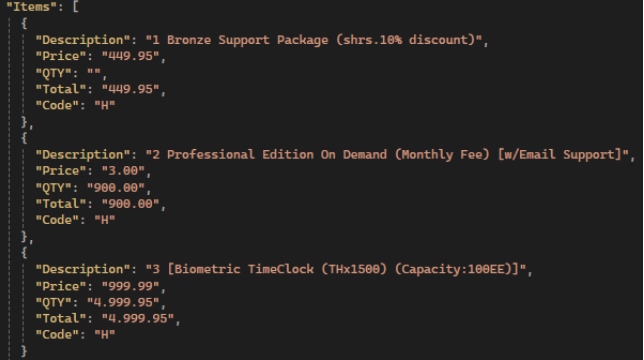
Deepseek: Most of values are incorrect or absent, bad text in text attributes:
Cost Comparison
|
Service |
Cost |
Cost per page (average) |
|---|---|---|
|
$10 / 1000 pages 1 |
$0.01 |
|
|
$10 / 1000 pages |
$0.01 |
|
|
$10 / 1000 pages |
$0.01 |
|
|
$2.50 / 1M input tokens, $10.00 / 1M output tokens 2 |
$0.021 |
|
|
$2.50 / 1M input tokens, $10.00 / 1M output tokens |
$0.0087 |
|
|
$1.25, input prompts ≤ 128k tokens |
$0.0045 |
|
|
$10 / 1000 pages + $0.27 / 1M input tokens, $1.10 / 1M output tokens |
$0.011 |
Notes:
1 — $8 / 1000 pages after one million per month
2 — Additional $10 per 1000 pages from using a text recognition model
Conclusion & Key Findings
This comprehensive evaluation of seven invoice extraction solutions—AWS, Azure, Google AI, GPT-4o (text & image), Gemini, and Deepseek—revealed critical insights into their accuracy, efficiency, and limitations. Below is a consolidated summary of the findings:
Model Performance & Accuracy
- Azure AI struggled with multi-word item descriptions (e.g., employee names), significantly reducing its efficiency (33.3% on Invoice 5).
- Google AI failed to provide structured item breakdowns, combining all attributes into a single string, making it unsuitable for automated workflows.
- Gemini demonstrated the highest detailing capability, accurately extracting extended fields when prompted, outperforming other LLMs (GPT-4o, Deepseek).
- GPT-4o (image input) performed well but had occasional inaccuracies in numerical values.
- Deepseek showed lower reliability, with frequent errors in text and numerical extraction.
Impact of Invoice Quality
- Low resolution had minimal impact on detection quality, except for rare formatting errors (e.g., comma misrecognition in Deepseek).
- Multi-line item descriptions did not degrade performance in most models, except for Google AI.
- Unconventional invoice structures (missing fields, sub-items) caused detection failures across all models, leading to the exclusion of two problematic samples.
Efficiency & Cost Considerations
- Efficiency (Eff, %) was calculated based on strict/non-strict field matches and item-level accuracy, with Gemini and GPT-4o leading in consistency.
- Cost models varied between text-based (token usage + OCR) and image-based (tokenized image processing), with LLMs (Gemini, GPT) incurring higher expenses for detailed extraction.
Final Recommendations
- For structured, high-accuracy extraction: Gemini (best for detailed fields) or AWS/Azure (for fixed attribute extraction).
- For cost-effective OCR + LLM processing: GPT-4o (text input with third-party OCR) strikes a balance between accuracy and affordability.
- Avoid Google AI if item-level breakdowns are required.
- Test edge cases before deployment—models struggle with non-standard invoice formats.
Future Considerations
- Fine-tuning LLM prompts could further improve extraction quality.
- Hybrid approaches (e.g., AWS OCR + Gemini for item detailing) may optimize cost and accuracy.
This research highlights that no single solution is perfect, but the optimal choice depends on the use case—whether prioritizing precision, cost, or structured output.