Newspapers and magazines are one of the most challenging documents to automatically process: their complex structure requires a thought out approach to creating a processing system. Having had experience working on multiple newspaper digitization systems, we have a deep understanding of the development process, and in this article we aim to describe a viable approach to creating newspaper processing software using AI.
Newspapers: Processing Challenges
Newspapers represent a complex frontier for automated processing systems due to their inherently unstructured nature. Unlike structured documents, where specific data types are located in predictable places, newspapers are designed for human readers, not algorithms, making them challenging to process using automated systems.
We at Businessware Technologies, however, have developed various complex document processing systems, including AI newspaper processing software. Having lots of experience in this field, we are closely familiar with challenges that automatic newspaper processing systems can present.
Newspapers Are Unstructured Documents
One of the primary obstacles in processing newspapers with AI is the lack of a uniform structure. Each page of a newspaper might contain a myriad of elements — headlines, articles, images, and advertisements — all arranged in a way that maximizes space and reader engagement but confounds standard data extraction algorithms.
Irregular Article Structure
Newspapers do not follow a standard template. The beginning and end of articles are not consistently marked, and multiple articles can be juxtaposed on the same page with only subtle visual cues separating them. This layout variety poses a significant challenge for AI systems, which typically rely on consistent patterns for data extraction and analysis.
AI technologies must be adept at understanding and interpreting varied layouts, a task that often involves advanced computer vision techniques combined with natural language processing. The AI needs to differentiate between headlines, subheadlines, captions, and main article text, which can vary drastically in style and location from one newspaper to another.
Use Of Images
Incorporating images within text adds another layer of complexity. Newspapers frequently use photographs, charts, and other graphical elements to supplement or convey information relevant to the text. These images are often accompanied by captions that may not follow the main text's flow and are positioned based on available space rather than a standard layout.
To effectively process newspapers, AI systems must not only recognize and extract text but also understand the relationship between text and accompanying images. This involves discerning whether an image illustrates the article's content or serves a decorative or advertising purpose. AI tools must be capable of contextual analysis to determine the relevance and significance of images in relation to the text.
Processing Newspapers With AI
There are multiple approaches to extracting articles from newspapers and magazines, in this article we are going to describe one based on the use of LLMs: a rather simple, but effective approach to extracting text data from complex documents.
Text Extraction
The first step of any document recognition process is detection of text data. For documents with a text layer this process is fairly simple as it requires a simple extraction of a text layer. On the other hand, documents without a text layer require a different approach: first, a computer vision model needs to process the document to detect letters, numbers and other text data, after which the data can be extracted in a form of a formatted text.
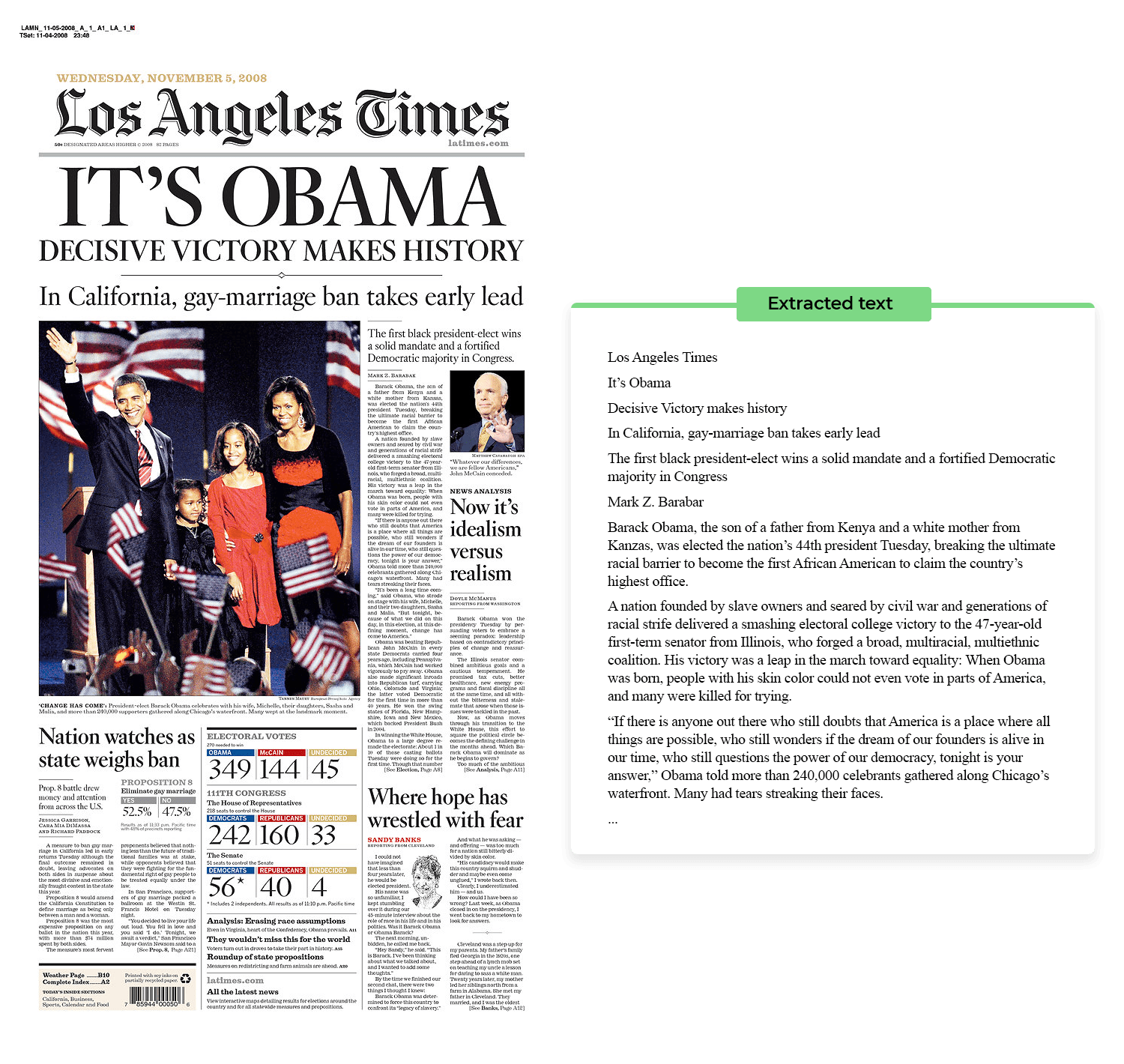
Text Coordinates
Determining text location on a page is an important step as it lays a bridge between text data and LLM data analysis. Most AI text processing tools, like Azure Document Intelligence, are capable of both extracting text and detecting its coordinates, so this step usually doesn’t involve additional programming.
Using text coordinates, the text can be separated into lines and paragraphs, as well as formatted to reflect the page structure.
Detecting Articles With LLMs
After the text is formatted, it is passed on to an LLM for processing. We can ask an LLM to separate the text into articles based on mainly text meaning and topics, but also its overall formatting.
There are multiple LLMs on the market capable of efficiently processing text and “understanding” its meaning, the choice of a model for your project depends on multiple factors, like cost per token, desired level of data security, processing power, etc.
In this example we’ve used GPT 4o to separate text into articles.

Detecting Articles on the page
We now have a set of articles separated by an LLM. This data needs to be passed down to the visual processing module to determine article boundaries on the newspaper page based on text coordinates we’ve obtained earlier.

Article Detection Improvement Techniques
While this approach generally works well for most newspaper and magazine layouts and provides decent article detection quality, there’s always room for improvement, especially when it comes to more complex layouts, like Chinese newspapers.
Title Position Detection
One of the most common article detection mistakes is the wrong placement of an article bounding box due to complex article structure. When a page features multiple articles, images and subheaders on one page, computer vision algorithms struggle to determine article edges.
Article title can help with refining the bounding box: by enforcing the rule that an article must always be below its title, we’ve seen a decent improvement in article detection quality.
Paragraph-based Article Detection
Another technique that can be implemented to combat inaccurate article detection is implementing paragraph-based article detection. Based on individual paragraph’s coordinates, text is separated into blocks, and if the article is detected within one of these blocks, its bounding box can’t go outside of the block.
Segmentation Model
Introducing a segmentation model is a more complex approach to newspaper article detection, but the one that provides the best results in practice. Using computer vision techniques, you can train a segmentation model to automatically detect article boundaries with high accuracy.
However, we must note this approach requires a dataset of newspapers with a similar layout to the ones you need to process, as well as a team of seasoned machine learning experts to perform CV model training, testing, and implementing.
Looking for AI developers?
We create AI software — and we do it well. Talk to us to get your project started today
Why choose Businessware Technologies as your AI development company?
- Businessware Technologies is a reliable AI development vendor: it has been recognised as one of the top software development companies by Clutch and Manifest, it is a Top Rated Plus agency Upwork, and has received local awards for its excellent work,
- A team of over 70 highly skilled software engineers, including an AI department of over 40 seasoned professionals, with extensive experience in developing complex software for both startups and Fortune 500 companies,
- Deep expertise in modern AI technologies and approaches to system development, like data science, machine learning, LLMs, OpenCV, Python, Tesseract, and many more,
- Businessware Technologies is a Microsoft Gold Certified partner,
- Businessware Technologies is compliant with GDPR, ISO 9001, ISO 27001 standards,
- Businessware Technologies works with Fortune 500 companies and has had decades-long relationships with most of its clients,
- Businessware Technologies has proven to be a reliable AI outsourcing partner by having an excellent track record in AI and ML development backed by an extensive portfolio of successful projects.
If you have a document processing project in mind and need help with implementation, contact our manager and they will be happy to help you.